

2.1 信息存储
- 计算机使用 字节 (byte,8 位)作为最小的可寻址内存单位
- 机器级程序将内存视为一个非常大的字节数组,称为 虚拟内存
- 内存的每个字节都由一个唯一的数字来标识,称为它的 地址
- 所有可能的地址集合称为 虚拟地址空间
2.1.1 十六进制表示法
- C语言中,用
0x或0X开头的数字表示十六进制
2.1.2 字数据大小
-
每台计算机都有一个字长,指明指针数据的标称大小
- 因为虚拟地址是以这样的一个字来编码的,所以字长决定的最重要的系统参数就是虚拟地址空间的最大大小。对于一个字长为
w位的机器而言,虚拟地址的范围为 $0 \sim 2^w - 1$,程序最多访问 $2^w$ 个字节
- 因为虚拟地址是以这样的一个字来编码的,所以字长决定的最重要的系统参数就是虚拟地址空间的最大大小。对于一个字长为
-
大多数 64 位机可以运行 32 位机编译的程序,这是一种向后兼容
- 因此,我们所说的程序位 32 位程序或 64 位程序时,区别在于该程序是如何编译的,而不是其运行的机器类型
-
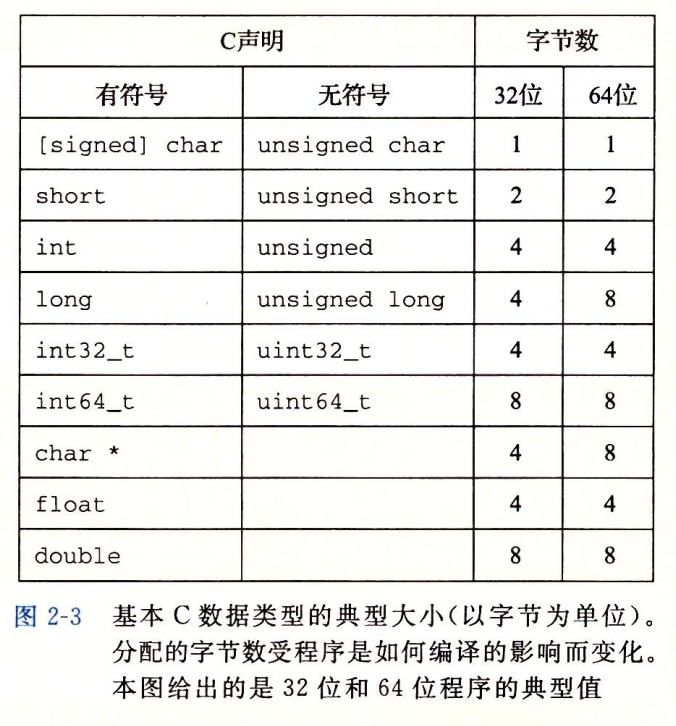
基本 C 数据类型在 32 位程序和 64 位程序中的典型大小如下图
2.1.3 寻址和字节顺序
-
小端序:最低有效字节在前
-
大端序:最高有效字节在前
-
假设变量
x的类型为 int,位于地址0x100处,他的十六进制值为0x1234567。地址范围0x100 ~ 0x103。 地址0x100 ~ 0x103的字节顺序依赖于机器的类型:
-
在C语言中,可以通过使用 强制类型转换 或 联合 来允许以一种数据类型引用一个对象,而这种数据类型与创建这个对象时定义的数据类型不同。
2.1.4 表示字符串
- C语言中字符串为一个以
null(其值为0)字符结尾的字符串数组,每个字符都由某个标准编码来表示,最常见的是 ASCII 字符码。十进制数x的 ASCII 码正好是0x3x,而终止字节的十六进制表示为0x00
2.1.5 表示代码
-
考虑下面 C 函数:
int sum(int x,unt y) { return x+y; }当在实例机器上编译时,生成如下字节表示的机器代码:

不同的机器类型使用不同的且不兼容的指令和编码方式。即使是完全一样的进程,运行在不同的操作系统上也会有不同的编码规则,因此二进制码是不兼容的。二进制码很少能在不同的机器和操作系统组合之间移植。
2.1.6 布尔代数简介
- 布尔代数表
| 布尔运算 | 名字 | 逻辑运算符 | 在命题中的符号 | 真值描述 |
|---|---|---|---|---|
| ~ | 否 | NOT | ┐ | 若p为真,则┐p为假 |
| & | 合取 | AND | ∧ | 只有当p,q都为真时,p∧q为真 |
| | | 析取 | OR | ∨ | 只有当p,q为假是,p∨q为假 |
| ^ | 异或 | EXCLUSIVE~OR | ⊕ | p,q为真但不同时为真时,p⊕q为真 |
- 位向量:固定长度
w、由 0 和 1 组成的串。位向量的运算可以定义成参数的每一个对应元素之间的运算。假设a和b分别表示位向量 $[a_{w-1},\dots,a_0]$ 和 $[b_{w-1},\dots,b_0]$。那么 $a\&b$ 则表示为长度为w,第i个元素为 $a_i\& b_i, (0<=i^、~也可以这样写。 - 位向量一个很有用的应用就是表示有限集合。例如:
- 位向量 $a=[01101001]$ 表示 $A=\{0, 3, 5, 6\}$
- 因为 $a_0$ 是在右边的,从右往左看,第几位是1,就表示了第几位存在
- 布尔运算的
|和&分别表示集合里的并和交,而~表示补
2.1.7 C语言中的位级运算
- C语言支持按位布尔运算:
~、&、|
2.1.8 C语言中的逻辑运算
- C语言中提供了一组逻辑运算符
||、&&、!
2.1.9 C语言中的移位运算
<<:左移,x<<n等价于 $x×2^n$>>:右移,x>>n等价于 $x÷2^n$
注意!在C语言中,移位运算符、逻辑运算符、位级运算符的优先级均低于 +/-
2.2 整数表示
2.2.1 整型数据类型


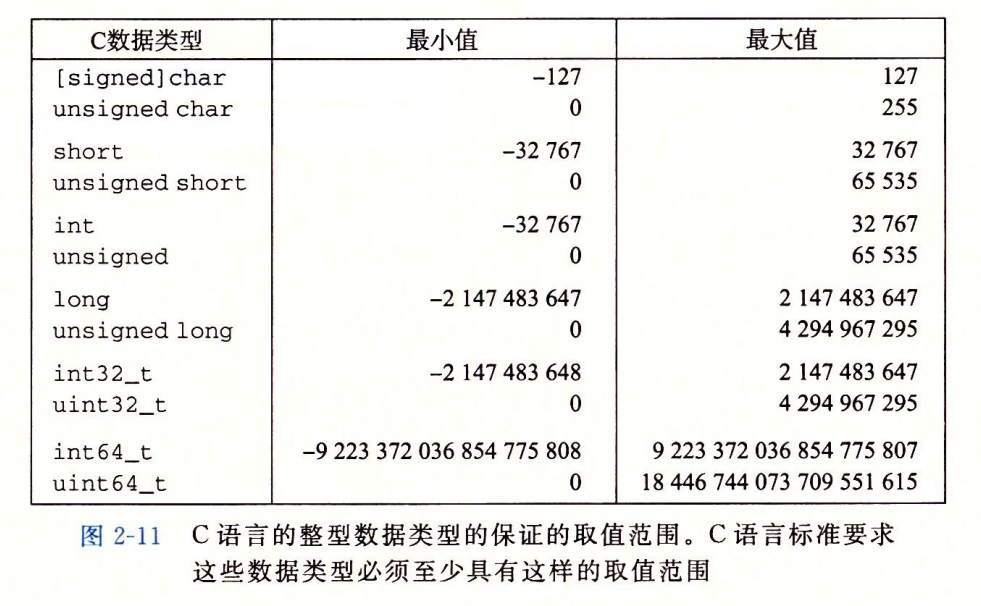
- C 和 C++ 都支持有符号(默认)和无符号数。Java 只支持有符号数。
2.2.2 无符号数的编码
- 把向量
x看作一个二进制表示的数,就获得了x的无符号表示。 - 在这个编码中,每个位 $x_i$ 都取值为 0 或 1,后一种取值意味着数值 $2^i$ 应为数字值的一部分
2.2.3 补码编码
-
有符号数的计算机表示方式是补码形式,将字的最高位解释为负权,它也被称为符号位,符号位设置为 1 时,表示值为负,当设置为 0 时,值为非负
-
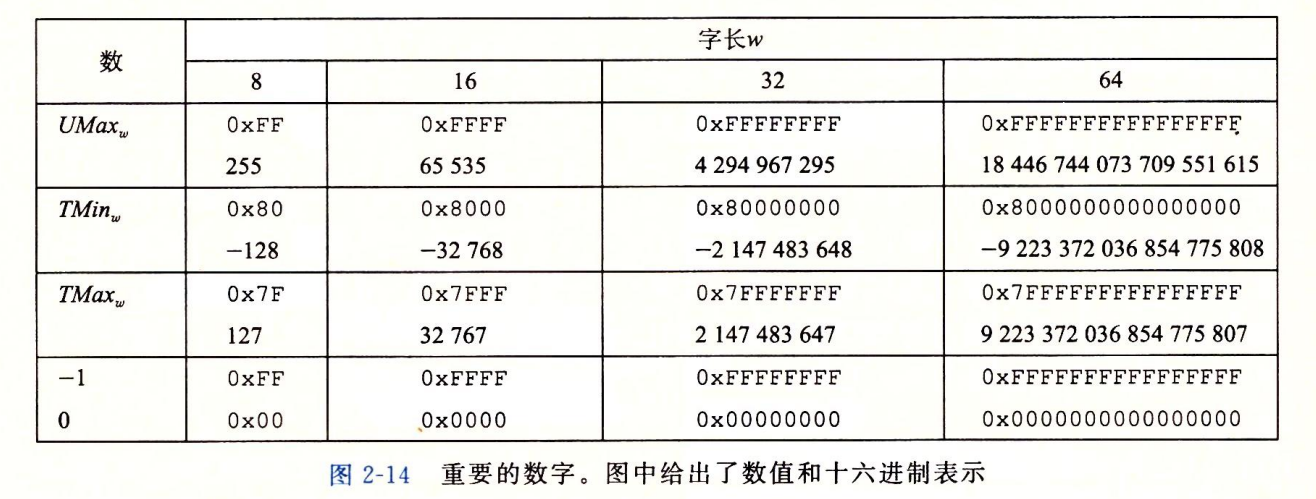
几个重要数字的数值和十六进制表示
-
注意
- 补码的范围是不对称的,$|TMin|=|TMax|+1$,$TMin$没有与之对应的正数,这导致了补码的一些性质和容易造成的错误。这是因为符号位为区分了负数和非负数,而 0 是非负数,所以正数比负数少一个
- 最大的无符号数值刚好比有符号数值的两倍大一点:$UMax_w=2TMax_w+1$
- C库中的文件
<limist.h>定义了一组常量,来限定编译器运行的这台机器的不同整数数据类型的取值范围。
-
关于整数数据类型的取值范围和表示,Java 标准是非常明确的,它要求采用补码形式表示。在 Java 中,单字节数据被称为 byte 而不是 char。这些非常具体的要求都是为了保证无论在什么机器上运行,Java 程序都能表显地完全一样。
2.2.4 有符号数和无符号数之间的转换
- 规则:数值可能会改变,但是位模式不变
2.2.5 C语言中的有符号数和无符号数
-
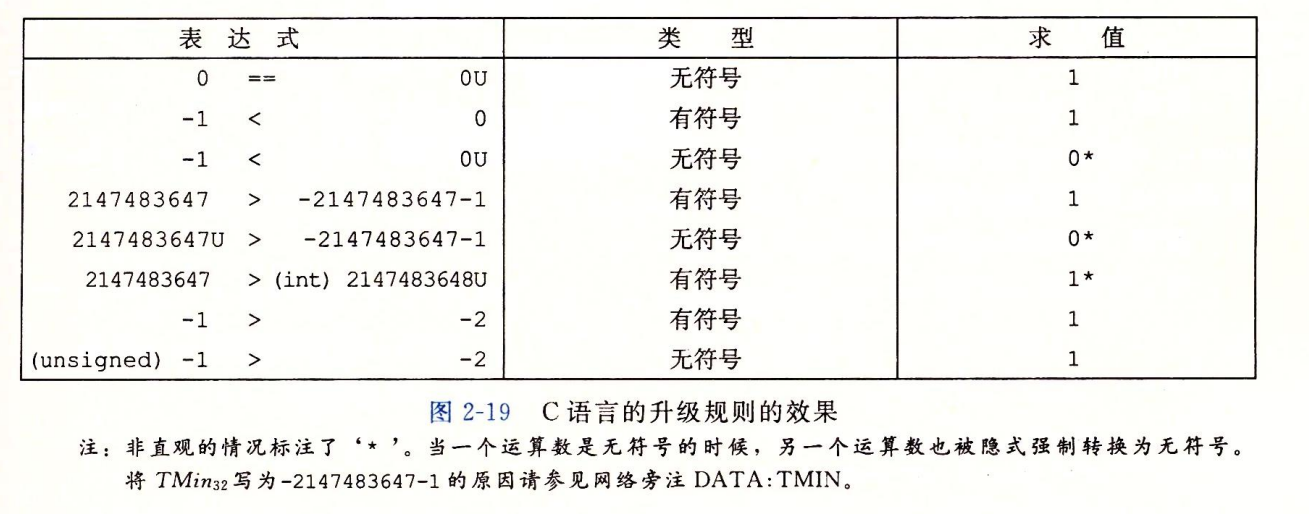
当进行逻辑运算时,算式中有一个数是无符号的数,另一个数也会被隐式转换为无符号数再进行比较,于是会产生一些不够直观的效果
2.2.6 扩展一个数字的位的表示
- 零扩展:将一个无符号数转换为一个更大的数据类型,在表示的开头添加 0
- 补码的符号扩展:将一个补码数转换为一个更大的数据类型,在表示的前面添加最高有效位的值
2.2.7 截断数字
- 截断:大数变小数(减少表示一个数字的位数),将一个
w位的数截断为一个k位的数时,丢弃高w-k位
2.3 整数运算
2.3.1 无符号加法
- 对$0\leq x,y<2^w$,若 $x+y \geq 2^w$,则进行高位截断,即计算结果保留到 $w$ 位。定义 $+{}_w^u$ 表示无符号加法,公式如下:
2.3.2 补码加法
-
与无符号数加法类似
-
定义 $x+{}_w^ty$ 为整数和 $x+y$ 被截断为 $w$ 位的结果,并将这个结果看作是补码数。公式如下:
2.3.3 补码的非
- 对 $TMin_w \leq x \leq TMax_w$,$x$ 的补码为:
- 对任何$x$,$-x+x=0$
2.3.4 无符号乘法
- 对 $0\leq x,y
2.3.5 补码乘法
- 对 $TMin_w\leq x,y\leq TMax_w$,定义 $x*{}_w^ty$ 为 $x*y$ 被截断为 $w$ 位的结果。公式如下:
- 其中,$U2T_w$ 表示将无符号数转换为补码数
2.3.6 乘以常数
- 计算机运算乘法速度相对较慢,编译器做了优化,试着用移位和加法运算的组合来代替乘以常数因子的乘法。
- 左移一个数值等价于执行一次与 2 的幂相乘的无符号乘法
- 一个常数 $K$ 的二进制可以表示成一组 0 和 1 交替的序列$[(0\cdots 0)(1\cdots 1)(0\cdots 0)\cdots (1\cdots 1)]$,考虑一组从位置 $n$ 到位置 $m$ 连续的 1 ($n\geq m$),可以用下面两种形式之一来计算他们的和:
- 形式 A:$(x<
- 形式 B:$(x<<(n+1))-(x<
- 形式 B:$(x<<(n+1))-(x<
- 形式 A:$(x<
2.3.7 除法
部分内容参考:编译器除法优化
-
整数除法要比整数乘法更慢,要30个或更多时钟周期
-
整数除法总是舍入到零,满足如下公式:
$$ \begin{aligned} & x/y=\lfloor x/y\rfloor, & x\geq 0,y>0 &\\ & x/y=\lceil x/y\rceil, & x<0,y>0 &\\ \end{aligned} $$ -
整数除法同样可以用移位和加减法组合做运算,这里使用右移。无符号和补码数分别用逻辑移位和算数移位。
-
根据除数是否是 2 的幂,可以分为两种情况进行优化
对于除以2的倍数优化
- 对于要进行除法运行的且除数是 2 的倍数,可以通过位移来完成,但是对于负数来说,直接位移可能发生错误:
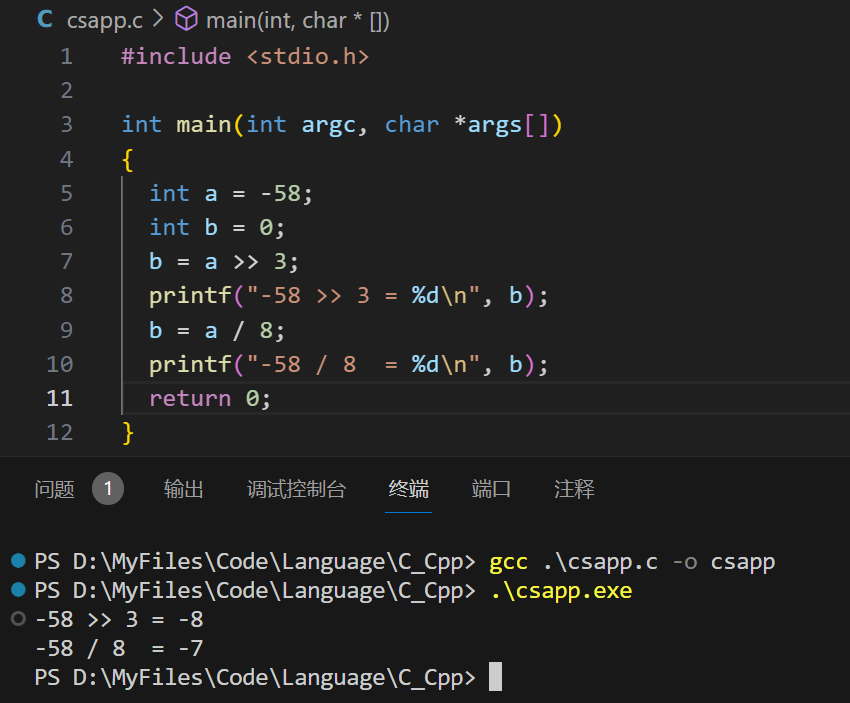
此时可以通过偏置技术解决。如下公式:
$$ b>0,\left\{ \begin{align} & \lfloor \frac a b \rfloor =\lceil \frac {a-b+1} b \rceil &\\ & \lceil \frac a b \rceil =\lfloor \frac {a+b-1} b \rfloor & \end{align} \right. $$$$ b<0,\left\{ \begin{align} & \lfloor \frac a b \rfloor =\lceil \frac {a-b-1} b \rceil &\\ & \lceil \frac a b \rceil =\lfloor \frac {a+b+1} b \rfloor & \end{align} \right. $$
以 $a=-58,b=8$ 为例,结合上式(2),可以得到:
$$ \begin{aligned} \lceil \frac {-58} 8 \rceil &=\lfloor \frac {-58+8-1} 8 \rfloor\\ &=\lfloor \frac {-51} 8 \rfloor\\ &=\lfloor -6.375 \rfloor\\ &=-7 \end{aligned} $$对于除以非2倍数优化
- 利用如下公式:
- 反推可得:
其中 $M$ 是常量所以可以被编译器优化为编译常量,其中 $n$ 至少为32($n$ 越大结果越精确)
2.4 浮点数
浮点表示对形如 $V=x\times 2^y$ 的有理数进行编码
IEEE754 是一个仔细指定的表示浮点数及其运算的标准
2.4.1 二进制小数
- 一种关于二进制的小数编码:
- 小数的二进制表示
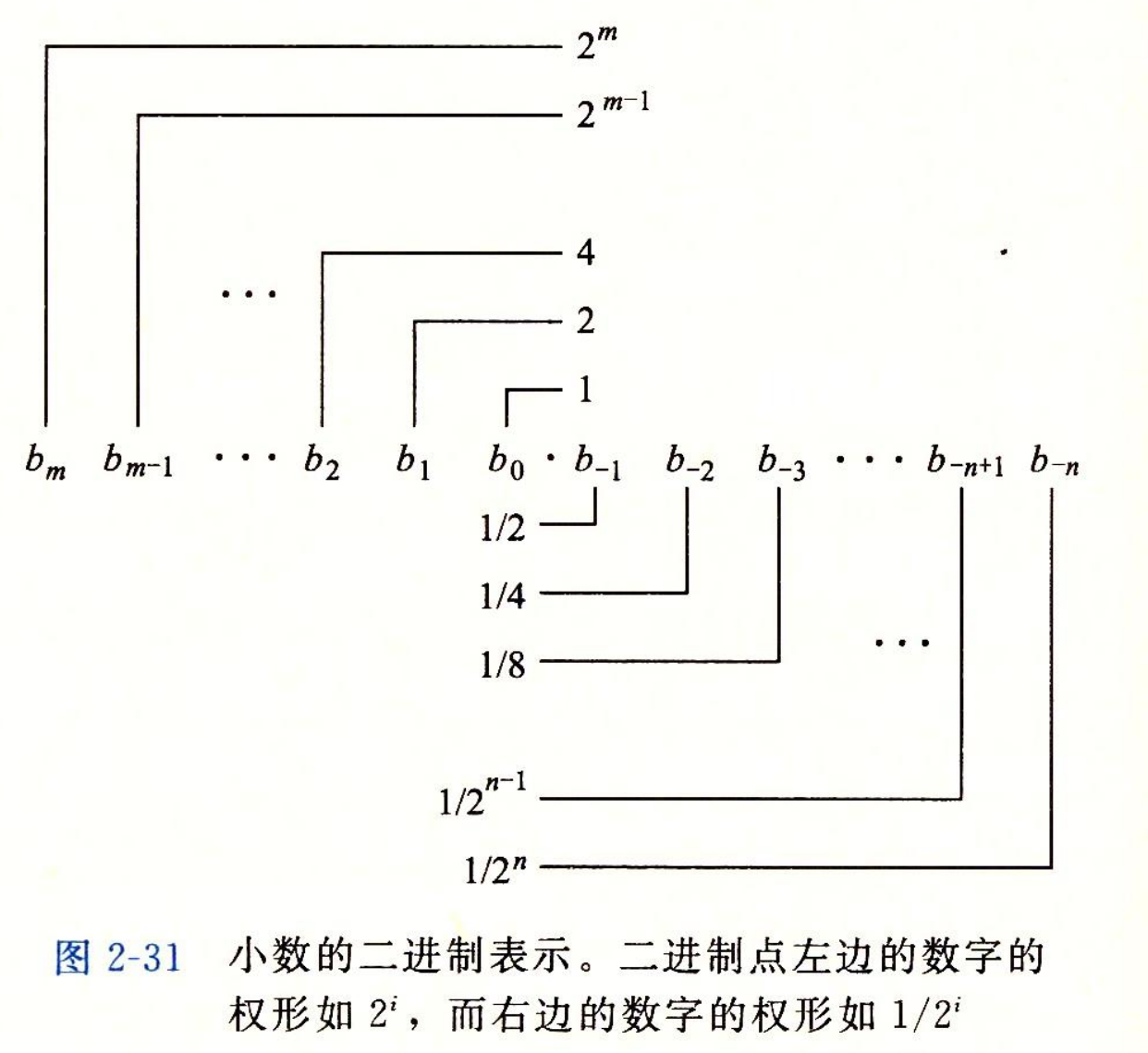
- 二进制小数点向左移动一位相当于这个数被 2 除,二进制小数点向右移动一位相当于将数乘 2
2.4.2 IEEE浮点数表示
-
IEEE浮点标准用 $V=(-1)^s\times M\times 2^E$ 的形式来表示一个小数:
- 符号 $s$ —— 决定这个数是负数($s = 1$)还是正数($s = 0$)
- 尾数$M$ —— $M$是一个二进制小数,它的范围是 $[1.0, 2.0)$,或者$[0,1.0)$,$n$ 位小数字段$frac = f_{n-1}\dots f_1f_0$ 编码成尾数 $M$
- 阶码 $E$ —— $E$ 的作用是对浮点数加权,这个权重是 $2^E$(可能是负数)$k$ 位的阶码字段 $exp=e_{k-1}\dots e_1e_0$ 编码成阶码 $E$
-
C语言中的编码方式:
- 单精度浮点格式(float) —— $s$、$exp$ 和 $frac$ 字段分别为 1 位、$k = 8$ 位和 $n = 23$ 位,得到一个 32 位表示
- 双精度浮点格式(double) —— $s$、$exp$ 和 $frac$ 字段分别为 1 位、$k = 11$ 位和 $n = 52$ 位,得到一个 64 位表示

-
根据 $exp$ 的值,被编码的值可以分成三种不同的情况:

- 规格化的值——$exp$ 的位模式:既不全为 0(数值 0),也不全为 1(单精度数值为 255,双精度数值为2047)
- 阶码的值:$E = e - Bias$(偏置编码法)
- 其中 $e$ 是无符号数,其位表示为 $e_{k-1}\dots e_1e_0$,单精度下取值范围为 1
254,双精度下取值范围为 12047 - Bias 是 $2^{k-1} - 1$,单精度下是 127,双精度下是 1023
- 因此阶码 $E$ 的取值范围:单精度下是 -126~+127。双精度下是 -1022~1024
- 其中 $e$ 是无符号数,其位表示为 $e_{k-1}\dots e_1e_0$,单精度下取值范围为 1
- 尾数的值:$M = 1 + f$(隐式编码法)
- 其中 $0\leq f<1.0$,$f$ 的二进制表示为 $0.f_{n-1}\dots f_1f_0$,也就是二进制小数点在最高有效位的左边。因此添加了一个隐含的 1, $M$ 的取值范围为 $1.0\leq M < 2.0$
- 阶码的值:$E = e - Bias$(偏置编码法)
- 非规格化值——$exp$ 的值为 0
- 阶码的值:$E = 1 - Bias$
- 尾数的值:$M = f$(没有隐含的 1)
- 非规格化数有两个用途:
- 表示数值 0 —— 只要尾数 M = 0
- 表示非常接近于 0.0 的数
- 特殊值——$exp$ 的位模式为全 1
- 当小数域全为 0 时,得到的值表示无穷,当 $s = 0$ 时是 $+\infty $,当 $s = 1$ 时是 $-\infty$
- 当小数域为非零时,得到 $NaN$(Not a Number)
- 规格化的值——$exp$ 的位模式:既不全为 0(数值 0),也不全为 1(单精度数值为 255,双精度数值为2047)
